「C++のためのAPIデザイン」読んだ+ちょっとした補足

- 作者: マーティン・レディ,Martin Reddy,三宅陽一郎,ホジソンますみ
- 出版社/メーカー: ソフトバンククリエイティブ
- 発売日: 2012/11/02
- メディア: 大型本
- 購入: 4人 クリック: 106回
- この商品を含むブログ (9件) を見る
どんな本か
この本は、誰かに使ってもらうためのソフトウェアを(主にC++で)書く際に役立つ本です。APIというと外部ユーザーに使ってもらうためのソフトウェアインターフェースだけを指すようにも感じられますが、この本で言うAPIとはもっと広い意味で、
自分が書いたコードを使う全ての人に対してコードの操作方法を定義するヘッダ、ライブラリ、ドキュメント
を指しています。また、扱う内容もAPIの設計原則からアーキテクチャ設計手法、スタイル、実装テクニック、パフォーマンス、バージョン管理、自動テスト等、設計〜保守に至るまで多岐に渡っています。
APIの善し悪しに関しては私自身感覚的な判断でやってきた部分が結構あるので、拠り所となる日本語の書籍が1冊あると、社内でのコードレビューとか新人の教育にも役立ってくれそうな予感がします。類書として「大規模C++ソフトウェアデザイン」もありますが、どちらかを選ぶのであれば内容の広範さと日本語としての読みやすさ、内容の新しさから本書を推したいです。
どんな人におすすめか
自分のコードを使うのは並行開発する同僚だったり、未来の自分だったりもするので、ライブラリの作成者だけではなく、大規模プロジェクトでC++を使おうとする人にはぜひ読んでほしいなあと思える内容です。なお、C++に限らない記述も多いため、非C++erでも役に立つのではと思いますが、基本的なC++の文法を知っていないと読みにくいかもしれません。
補足したい所
内容は筆者の開発経験とC++の知識に基づいていてとても勉強になるのですが、重箱の隅的な部分でいくつか補足しておきたい部分があるので自分用メモを兼ねて書いておきます。
「STLアルゴリズムの選択はコンテナには依存しない(2.4.4, p.56)」は厳密ではない
たとえばstd::sortはstd::vectorやstd::dequeには使えますが、std::listには使えません。コンテナごとにイテレータカテゴリが違うため、アルゴリズムが要求するイテレータの要件を満たさない場合はコンパイルが通りません。
また、p.52では「異なるSTLコンテナが同名のメンバ関数を持つため、あるコンテナの使い方が分かれば別のコンテナの使い方も分かる」旨の解説がありますが、これも厳密ではないかなと感じました(使い方が分かる、のレベルとしてどれ位を想定するのか次第ですが)。例えシグネチャが同じメソッドでも、コンテナによって例外安全に対する保証が異なる、計算量が異なる、イテレータの無効化タイミングが異なるといった機能面での差があるということは認識しておいたほうが良いと思います。詳しくはEffective STL 第2項「コンテナに依存しないコードという幻想に注意しよう」あたり。
RAIIが必要である理由は、returnステートメントだけではない(2.4.5, p.60)
リソースの確保・解放はコンストラクタとデストラクタでやるべきというのはC++としては当たり前の話ではあります。本書ではその例として、以下のコードが挙げられていました。
void SetName(const std::string& name) { mMutex.lock(); if (name.empty()) { return; } mName = name; mMutex.unlock(); }
説明の流れとしては、このコードはreturn時のunlockが抜けているのでデッドロックが起きる→RAIIを使えばreturnステートメントを1つずつチェックする必要がなくなる、みたいな感じだったのですが、実際にはmName = nameの代入演算で例外を送出する*1という関数の抜け方があるため、return文だけのチェックでも十分ではありません。それを考えると、RAIIを使わずにリソースリークを起こさないコードを正確に書くのは、より困難になります。
void SetName(const std::string& name) { try { mMutex.lock(); if (name.empty()) { mMutex.unlock(); return; } mName = name; mMutex.unlock(); } catch (...) { mMutex.unlock(); throw; } }
結論は一緒ですが、理由としては複数return文の場合に困るというより、例外に備えたリソース確保を書くのが大変というほうが大きいように思います。
「コンパイラが暗黙に生成するメソッドは4つ(6.2, p.209)」とは限らない
C++11であればムーブコンストラクタとムーブ代入演算子も加えた6つのメソッドが暗黙に生成されます。C++11環境でのクラス定義の方針は、以下が参考になります。
「STL文字列の実装のほとんどはCoW(7.7, p.278)」は2013年現在では正しくない
以前はそうだったのですが、現時点では少なくともVC, clangではstd::stringはCoW(書き込み時コピー)を使っていません。さらに、C++11では規格上CoWでのstring実装ができないような文面になっています。
参考:
c++ - Legality of COW std::string implementation in C++11 - Stack Overflow
C++03 と C++11 の互換性 - melpon日記 - HaskellもC++もまともに扱えないへたれのページ
gccでは4.8時点でまだCoWが残っているようですが、C++11との整合性のためにいずれ消えていくはずです。CoWが使われない方向になっているのはマルチスレッド環境に対応するために必要な排他制御のコストがCoWのメリットを上回るからで(規格上禁止された経緯に関しては追ってないので分からない…)、自分のクラスでCoWをやろうとする場合も、他の最適化が使えないか*2検討した方が良いかと思います。CoWに関しては自分の知る限り「More Exceptional C++」が詳しいです。
例外安全はAPI設計に影響する
特に本書ではどこにも触れられていなかったのですが、C++でAPIを設計するに当たって、例外を使うことにした場合には「例外安全性はAPI設計に影響する」ことを考慮に入れなければなりません。本書では6章で以下のインターフェースを持つStack型が出てきます。
template <typename T> class Stack { public: void Push(T val); T Pop(); bool IsEmpty() const; private: std::vector<T> mStack; }
このPop()はどう実装しても例外安全の「強い保証」ができません*3。2013/5/15追記:Tの型とコンパイラの最適化次第では強い保証が満たせる状況が有る、との指摘を頂きました。コメント欄参照。例外安全にしっかりケアしたいのであれば、std::queueのようにPop()とTop()に分離するとか、API設計時点で配慮しておく必要が出てきます。
MinGWでも使える、gcovの出力をhtmlに整形するツール書いた
なにこれ
gcovが出力するテキスト形式のファイル(*.gcov)をhtmlに変換して、インデックスページを付けるツールです。
nyanp/gcovh · GitHub
使い方
gcc -coverage -o test test.c
プログラムを実行したら、gcovで.gcovファイルを生成。
gcov test.gcda
できたtest.c.gcovみたいなファイルを、このツールに突っ込みます。引数に複数ファイルを指定すれば、そいつらをまとめてhtmlに変換します。
gcovh test.c.gcov
そうすると、こんな感じの一覧できるインデックスと、

こんな感じのハイライトされたコードができます。オレンジは通過済みのパス、

たたみ込みニューラルネットをC++11とTBBで実装
たたみ込みニューラルネットとは
PRML5.5.6に出てくるアレ。1998年の以下の論文がたぶん初出。
Gradient Based Learning Applied to Document Recognition
7層前後の深い階層構造を持っており、最近流行りのdeep learningからすると恐らくご先祖のようなもの。論文中でもdeep learningみたく、「特徴抽出を問題ごとに手探りするのは止めて、生画像を深いネットワークに突っ込んで学習させた方がいいよね」という方向性をはっきり主張している。
The main message of this paper is that better pattern recognition systems can be built by relying more on automatic learning, and less on hand-designed heuristics.
Gradient Based Learning Applied to Document Recognition
-中略-
Using character recognition as a case study, we show that hand-crafted feature extraction can be advantegeously replaced by carefully designed learning machines that operate directly on pixel images.
論文に出てくる手書き数字認識用のLeNet5アーキテクチャはこんな形をしている。

細かい部分を全部省略すると、「5x5のフィルタを複数種類、複数段並べた特徴抽出部と、普通のニューラルネットによる識別部をまるごと全部繋げて、特徴抽出部のカーネル係数と識別部の重みを一緒に学習する」みたいなイメージ。図を眺めると、入力〜C5層までが入力を120次元ベクトルに変換する特徴抽出部、それ以降が3層ニューラルネットによる識別器と見えなくもない。
できたもの
nyanp/tiny-cnn · GitHub
Visual Studio 2012でリリースビルドするか、gccでCNN_USE_TBBを定義してビルドすれば、TBBを使った並列化版が出来る。中身はこんな感じ。
#include <iostream> #include <boost/timer.hpp> #include <boost/progress.hpp> #include "tiny_cnn.h" using namespace tiny_cnn; int main(void) { // LeNet-5ネットワークの構築 // RBFネットワークは省略し、6層としている typedef network<mse, gradient_descent> CNN; CNN nn; convolutional_layer<CNN, tanh_activation> C1(32, 32, 5, 1, 6); // input=32x32, window=5, in-channels=1, out-channels=6 average_pooling_layer<CNN, tanh_activation> S2(28, 28, 6, 2); // input=28x28, input-channels=6, pooling-size=2 // connection table [Y.Lecun, 1998 Table.1] static const bool connection[] = { true, false,false,false,true, true, true, false,false,true, true, true, true, false,true, true, true, true, false,false,false,true, true, true, false,false,true, true, true, true, false,true, true, true, true, false,false,false,true, true, true, false,false,true, false,true, true, true, false,true, true, true, false,false,true, true, true, true, false,false,true, false,true, true, false,false,true, true, true, false,false,true, true, true, true, false,true, true, false,true, false,false,false,true, true, true, false,false,true, true, true, true, false,true, true, true }; convolutional_layer<CNN, tanh_activation> C3(14, 14, 5, 6, 16, connection_table(connection, 6, 16)); average_pooling_layer<CNN, tanh_activation> S4(10, 10, 16, 2); convolutional_layer<CNN, tanh_activation> C5(5, 5, 5, 16, 120); fully_connected_layer<CNN, tanh_activation> F6(120, 10); nn.add(&C1); nn.add(&S2); nn.add(&C3); nn.add(&S4); nn.add(&C5); nn.add(&F6); // MNISTデータセットをロード std::vector<label_t> train_labels, test_labels; std::vector<vec_t> train_images, test_images; parse_labels("train-labels.idx1-ubyte", &train_labels); parse_images("train-images.idx3-ubyte", &train_images); parse_labels("t10k-labels.idx1-ubyte", &test_labels); parse_images("t10k-images.idx3-ubyte", &test_images); boost::progress_display disp(train_images.size()); boost::timer t; // 1epochごとに呼ばれるコールバック auto on_enumerate_epoch = [&](){ std::cout << t.elapsed() << "s elapsed." << std::endl; tiny_cnn::result res = nn.test(test_images, test_labels); std::cout << nn.learner().alpha << "," << res.num_success << "/" << res.num_total << std::endl; nn.learner().alpha *= 0.85; nn.learner().alpha = std::max(0.00001, nn.learner().alpha); disp.restart(train_images.size()); t.restart(); }; // 1dataごとに呼ばれるコールバック auto on_enumerate_data = [&](){ ++disp; }; // training nn.init_weight(); nn.train(train_images, train_labels, 20, on_enumerate_data, on_enumerate_epoch); // 結果表示 nn.test(test_images, test_labels).print_detail(std::cout); // 重みをファイルに書き出す std::ofstream ofs("LeNet-weights"); ofs << C1 << S2 << C3 << S4 << C5 << F6; //std::ifstream ifs("LeNet-weights"); //ifs >> C1 >> S2 >> C3 >> S4 >> C5 >> F6; }
template parameterで評価関数とか活性化関数とかを指定できるようにした。コールバックにlambdaが使えて嬉しい。MNISTのデータセットだと、60000枚の画像の学習が手元PC(4コア2.9GHz)では1周60秒。15分も回せば大体精度99%弱で収束するので、まあまあ速いんじゃないでしょうか。
TBBによる並列化
今回はバッチ学習ではなくstochastic diagonal Levenberg-Marquardtを使っているので、forward-propagation, back-propagationの中の積和計算を細かく並列化している。4コアで2.5倍前後の高速化。TBB有り無しであちこちに#ifdefをバラ撒くのが嫌だったので、以下のような簡単なヘルパを用意した。
typedef tbb::blocked_range<int> blocked_range; #ifdef CNN_USE_TBB template<typename Func> void parallel_for(int begin, int end, Func f) { tbb::parallel_for(tbb::blocked_range<int>(begin, end, 100), f); // TBB版 } #else template<typename Func> void parallel_for(int begin, int end, Func f) { blocked_range r(begin, end); f(r); // TBB無し版 } #endif // CNN_USE_TBB
このヘルパ関数を使って、もともとこういう形だったループは、
for (int i = 0; i < this->out_size_; i++) { for (int c = 0; c < this->in_size_; c++) l->update(current_delta[i] * prev_out[c], this->Whessian_[i*this->in_size_+c], &this->W_[i*this->in_size_+c]); for (int i = r.begin(); i < r.end(); i++) l->update(current_delta[i], this->bhessian_[i], &this->b_[i]); }
少しの変更でTBBあり/無しを切り替えられるようになった。
parallel_for(0,this->out_size_, [&](const blocked_range& r) { for (int i = r.begin(); i < r.end(); i++) for (int c = 0; c < this->in_size_; c++) l->update(current_delta[i] * prev_out[c], this->Whessian_[i*this->in_size_+c], &this->W_[i*this->in_size_+c]); for (int i = r.begin(); i < r.end(); i++) l->update(current_delta[i], this->bhessian_[i], &this->b_[i]); });
ラムダ+TBB素晴らしい。
バイトニック経路版の平面巡回セールスマン問題
巡回セールスマン問題(TSP)は有名なNP完全問題だが、ユークリッド平面におけるTSPは経路がbitonic tourであるという制約をつければ動的計画法で簡単に解けるようになる。以下そのメモ。
巡回セールスマン問題 - Wikipedia
bitonic tourとは
bitonic tourとは、左端の点から出発し、必ず左から右に向かって右端の点まで行き、つぎに右から左の方向に出発点まで戻ってくるような経路。wikipediaの図がわかりやすい。
Bitonic tour - Wikipedia, the free encyclopedia
解法
巡回するユークリッド座標上のN個の点を、x座標の昇順にソートした点列p1..pNを考える。1<=i
3つ目の式は図で表現するとこんな感じ。下図では、3つのうち経路最短となる真ん中が部分bitonic tourの最適解となる。

で、これはL[N][N]をボトムアップに埋めていく動的計画法に簡単に落とし込める。計算量はO(n^2)。
#include <iostream> #include <cmath> #include <limits> #include <vector> #include <utility> using namespace std; typedef pair<int, int> Point; double dist(const Point& p1, const Point& p2) { return sqrt(pow(p1.first - p2.first, 2.0) + pow(p1.second - p2.second, 2.0)); } double bitonic_tsp_distance(const vector<Point>& p) { const int N = p.size(); vector<vector<double> > L(N, vector<double>(N, 0.0)); for (int j = 1; j < N; j++) { for (int i = 0; i < j; i++) { if (i == 0 && j == 1) { L[i][j] = dist(p[i], p[j]); } else if (i < j - 1) { L[i][j] = L[i][j-1] + dist(p[j-1], p[j]); } else { L[i][j] = numeric_limits<double>::infinity(); for (int k = 0; k < i; k++) L[i][j] = min(L[i][j], L[k][i] + dist(p[k], p[j])); } } } double ans = numeric_limits<double>::infinity(); for (int k = 0; k < N-1; k++) ans = min(ans, L[k][N-1] + dist(p[k], p[N-1])); return ans; } int main(void) { vector<pair<int,int> > points; points.push_back(make_pair(0, 0)); points.push_back(make_pair(1, 6)); points.push_back(make_pair(2, 3)); points.push_back(make_pair(5, 2)); points.push_back(make_pair(6, 5)); points.push_back(make_pair(7, 1)); points.push_back(make_pair(8, 4)); cout << "answer:" << bitonic_tsp_distance(points) << endl; }
どういう時に使えそうか
普通に考えると、x座標が重複するような点群に対してはうまくいかない。また、(bitonic tourに限定されない)最適解に対して、精度の保証も取れない。普通のケースなら、O(n^2)で精度も最適解の2倍以下になる最近追加法でいい。DPが綺麗に適用できて面白いけど、実際の使いどころは無いのかなーという残念な結論。
ヘッダ1つでgoogle testっぽくテストが書けるpicotest書いた
以下に修正BSDライセンスで公開しておきます:
一応VC10/VC11(Win7),gcc4.6.2(Ubuntu)で動作確認。
これは何?
C++向けのユニットテスティングフレームワークです。ちょっとしたコードに対してテストを書きたいなー、でもわざわざテストのためにGoogle Testをリンクするのも、Boost.Testを引っ張り出すのも大げさ*1…みたいな時に使えるかもしれません。ヘッダだけで使えるテスティングフレームワークは他にもあります*2が、picotestは以下のような特徴があります。
サンプル
#include "picotest.h" int Factorial(int n) { return n == 0 ? 1 : n * Factorial(n - 1); } // 0 の階乗をテスト TEST(FactorialTest, HandlesZeroInput) { EXPECT_EQ(1, Factorial(0)); } // 正の数の階乗をテスト TEST(FactorialTest, HandlesPositiveInput) { EXPECT_EQ(1, Factorial(1)); EXPECT_EQ(2, Factorial(2)); EXPECT_EQ(6, Factorial(3)); EXPECT_EQ(40320, Factorial(8)); } int main(int argc, char **argv) { RUN_ALL_TESTS(); }
サンプルコードはgoogle testのドキュメントからほぼそのまま持ってきました。違いは(1)gtest.hの代わりにpicotest.hをインクルードしている点、(2)main関数でのtesting::InitGoogleTestの呼び出しが無い点、の2つのみです。逆にこの2点を修正すればpicotestからgoogle testに乗り換えることが可能です。
フィクスチャを使ったテストも、google testっぽく書けます。
template <typename E> // E is the element type. class Queue { public: Queue(); void Enqueue(const E& element); E* Dequeue(); // Returns NULL if the queue is empty. size_t size() const; ... }; class QueueTest : public ::testing::Test { protected: virtual void SetUp() { q1_.Enqueue(1); q2_.Enqueue(2); q2_.Enqueue(3); } // virtual void TearDown() {} Queue<int> q0_; Queue<int> q1_; Queue<int> q2_; }; TEST_F(QueueTest, IsEmptyInitially) { EXPECT_EQ(0, q0_.size()); } TEST_F(QueueTest, DequeueWorks) { int* n = q0_.Dequeue(); EXPECT_EQ(NULL, n); n = q1_.Dequeue(); ASSERT_TRUE(n != NULL); EXPECT_EQ(1, *n); EXPECT_EQ(0, q1_.size()); delete n; n = q2_.Dequeue(); ASSERT_TRUE(n != NULL); EXPECT_EQ(2, *n); EXPECT_EQ(1, q2_.size()); delete n; }
対応しているアサーション
| マクロ | 式 |
| ASSERT_TRUE(cond) | cond==true |
| ASSERT_FALSE(cond) | cond==false |
| ASSERT_EQ(expected, actual) | expected == actual |
| ASSERT_NE(expected, actual) | expected != actual |
| ASSERT_LT(expected, actual) | expected < actual |
| ASSERT_GT(expected, actual) | expected > actual |
| ASSERT_LE(expected, actual) | expected <= actual |
| ASSERT_GE(expected, actual) | expected >= actual |
| ASSERT_STREQ(expected_str, actual_str) | expected_str == actual_str(C文字列の比較) |
| ASSERT_STRNE(expected_str, actual_str) | expected_str != actual_str(C文字列の比較) |
| ASSERT_STRCASEEQ(expected_str, actual_str) | expected_str == actual_str(C文字列/大小文字を同一視) |
| ASSERT_STRCASENE(expected_str, actual_str) | expected_str != actual_str(C文字列/大小文字を同一視) |
| ASSERT_FLOAT_EQ(expected, actual) | expected == actual |
| ASSERT_DOUBLE_EQ(expected, actual) | expected != actual |
| ASSERT_FLOAT_NE(expected, actual) | expected == actual |
| ASSERT_DOUBLE_NE(expected, actual) | expected != actual |
すべてのマクロに対して、失敗するとテストケースを即座に抜けるASSERT_XXと、テストを続行するEXPECT_XXが用意されています。
できないこと
あくまで小規模コードをさくっとテストしたい場合を想定しているので、以下のような機能には対応していません。
あと、google test「っぽく」書けるとは言え、同じ挙動を保障するようなものでは無いことは一応書いておきます。
*1:google testはfused-src/以下に巨大な.ccと.hがあり、こいつらをプロジェクトに放り込めばリンクは不要になりますが、やっぱり個人的には面倒
*2:Boost.Test(boost/test/included以下)とか、CATCH(https://github.com/philsquared/Catch)とか
C#でEval
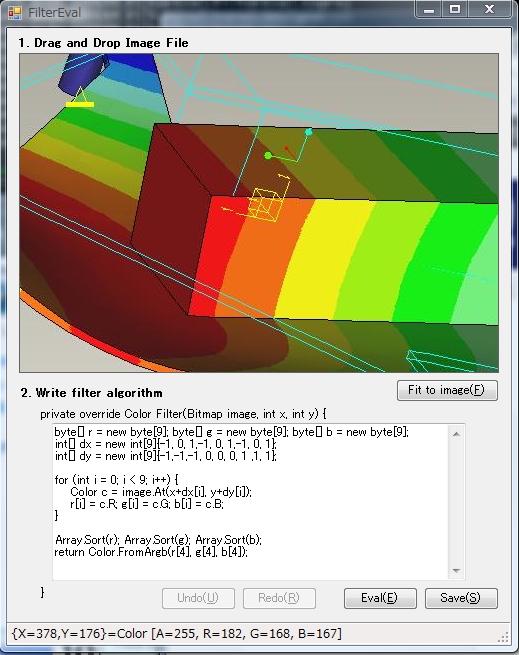
CSharpCodeProviderを使うとC#プログラム上でC#のコードをコンパイルして動作させる,要するにEvalみたいなことができる.で,アセンブリ参照に自分自身を指定してコンパイルすることで,Eval先から自分のpublic classを参照することができる.ということは,自分自身では抽象クラスだけ書いておき,Eval先で実装を埋めるという動的な(?)template methodパターンが作れる.
これは面白いなー有意義な使い道ないかなーということで,画像処理の簡単なテストが出来るアプリを書いてみた.
https://github.com/nyanp/FilterEval
やってることは超簡単で,まずコア関数をtemplateにした抽象フィルタを書く.
public abstract class AbstractFilter { private Bitmap src; public AbstractFilter(Bitmap image) { src = image; } public Bitmap Execute() { Bitmap dst = src.Clone(new Rectangle(0, 0, src.Width, src.Height), src.PixelFormat); for (int y = 0; y < b.Height; y++) { for (int x = 0; x < b.Width; x++) { dst.SetPixel(x, y, Filter(src, x, y)); } } return dst; } protected abstract Color Filter(Bitmap image, int x, int y); }
そしたらあとはTextBoxから文字列を取ってきて,Eval用の文字列とくっつけたらそれをコンパイル.これだけ.CSharpCodeEval.Evalは簡単なヘルパ関数.code projectに参考になるコードがあった.
Evaluate C# Code (Eval Function) - CodeProject
private Bitmap EvalFilter() { return (Bitmap)CSharpCodeEval.Eval(CreateFilterCode(textBox1.Text), "EvalTest.Evaler", "EvalCode", new object[1] { imageHistory[shownImageIndex] }); } private string CreateFilterCode(string coreCode) { StringBuilder sb = new StringBuilder(); sb.AppendLine("using System;"); sb.AppendLine("using System.Xml;"); sb.AppendLine("using System.Data;"); sb.AppendLine("using System.Drawing;"); sb.AppendLine("namespace EvalTest{ "); sb.AppendLine("public class EvalFilter : AbstractFilter { "); sb.AppendLine("public EvalFilter(Bitmap image) : base(image){ }"); sb.AppendLine("protected override Color Filter(BitmapPlus image, int x, int y) {"); sb.AppendLine(coreCode); sb.AppendLine("} "); sb.AppendLine("} "); sb.AppendLine("public class Evaler {"); sb.AppendLine("public object EvalCode(object image) {"); sb.AppendLine("EvalFilter e = new EvalFilter((Bitmap)image);"); sb.AppendLine("return e.Execute();"); sb.AppendLine("}"); sb.AppendLine("} "); sb.AppendLine("} "); return sb.ToString(); }
Bitmap.Getpixelはやたら遅いし,範囲外アクセスに対してケアするコードをEval側で書くのが正直面倒だったので,生配列にアクセスする以下の実装を貰い,ついでに範囲外アクセスを無理やり範囲内に矯正するAt(x,y)を追加.
NonSoft - Bitmap処理を高速化するサンプル(C#.NET)
ラプラシアンでもガウシアンでもぼくの考えたさいきょうのフィルタでもさくっと書いて試せるので結構便利.
doxygenのソースコードに手を加えて自前のフォーマットで簡易データ出力
今更説明するまでも無いような気もするけど,doxygenは多言語に対応しているソースコードのドキュメンテーションツール.出力フォーマットはhtml,LATEX,RTF等に対応しており,コード中のコメントを元にいい感じのドキュメントを生成してくれる.
しかし高機能であれこれ出力できる反面,必要な情報だけを簡潔にまとめたドキュメントが欲しいなーという時にはやや使いづらい面もあったり.今回,クラスメンバの一覧だけをコード中から取得したいなーという用途で良いツールが無かったので,doxygenのコードに手を加えてみることにした.
まず自前ビルドの環境を用意
ソースからビルドする方法は以下に記載されているので,基本的にはこれ通り進めばOK.
ただしMSVCでビルドする場合,BOMなしのutf-8を正しく認識できていないらしく,多言語対応用のヘッダ群(translator_xx.h)でビルドに失敗する.とりあえず今回は日本語以外いらないので,lang_cfg.hで定義されているLANG_JP以外のdefineをコメントアウトしてビルドを通した.
コードを読んでみる
doxygenのmain関数はいたってシンプル.
int main(int argc,char **argv) { initDoxygen(); readConfiguration(argc,argv); checkConfiguration(); adjustConfiguration(); parseInput(); generateOutput(); return 0; }
parseInput()が終わった段階で,グローバル変数の中にパースされた情報が入っている.具体的にはdoxygen.cppの100〜152行目.
// globally accessible variables ClassSDict *Doxygen::classSDict = 0; ClassSDict *Doxygen::hiddenClasses = 0; NamespaceSDict *Doxygen::namespaceSDict = 0; MemberNameSDict *Doxygen::memberNameSDict = 0; MemberNameSDict *Doxygen::functionNameSDict = 0; FileNameList *Doxygen::inputNameList = 0; // all input files FileNameDict *Doxygen::inputNameDict = 0; GroupSDict *Doxygen::groupSDict = 0; FormulaList Doxygen::formulaList; // all formulas FormulaDict Doxygen::formulaDict(1009); // all formulas FormulaDict Doxygen::formulaNameDict(1009); // the label name of all formulas PageSDict *Doxygen::pageSDict = 0; PageSDict *Doxygen::exampleSDict = 0; SectionDict Doxygen::sectionDict(257); // all page sections CiteDict *Doxygen::citeDict=0; // database of bibliographic references StringDict Doxygen::aliasDict(257); // aliases FileNameDict *Doxygen::includeNameDict = 0; // include names FileNameDict *Doxygen::exampleNameDict = 0; // examples FileNameDict *Doxygen::imageNameDict = 0; // images FileNameDict *Doxygen::dotFileNameDict = 0; // dot files FileNameDict *Doxygen::mscFileNameDict = 0; // dot files StringDict Doxygen::namespaceAliasDict(257); // all namespace aliases StringDict Doxygen::tagDestinationDict(257); // all tag locations QDict<void> Doxygen::expandAsDefinedDict(257); // all macros that should be expanded QIntDict<MemberGroupInfo> Doxygen::memGrpInfoDict(1009); // dictionary of the member groups heading PageDef *Doxygen::mainPage = 0; bool Doxygen::insideMainPage = FALSE; // are we generating docs for the main page? FTextStream Doxygen::tagFile; NamespaceDef *Doxygen::globalScope = 0; QDict<RefList> *Doxygen::xrefLists = new QDict<RefList>; // dictionary of cross-referenced item lists bool Doxygen::parseSourcesNeeded = FALSE; QTime Doxygen::runningTime; SearchIndex * Doxygen::searchIndex=0; QDict<DefinitionIntf> *Doxygen::symbolMap; bool Doxygen::outputToWizard=FALSE; QDict<int> * Doxygen::htmlDirMap = 0; QCache<LookupInfo> *Doxygen::lookupCache; DirSDict *Doxygen::directories; SDict<DirRelation> Doxygen::dirRelations(257); ParserManager *Doxygen::parserManager = 0; QCString Doxygen::htmlFileExtension; bool Doxygen::suppressDocWarnings = FALSE; ObjCache *Doxygen::symbolCache = 0; Store *Doxygen::symbolStorage; QCString Doxygen::objDBFileName; QCString Doxygen::entryDBFileName; bool Doxygen::gatherDefines = TRUE; IndexList Doxygen::indexList; int Doxygen::subpageNestingLevel = 0; bool Doxygen::userComments = FALSE; QCString Doxygen::spaces; bool Doxygen::generatingXmlOutput = FALSE;
クラス情報はDoxygen::classSDict, 名前空間はDoxygen::namespaceSDictあたりを手繰っていけば,だいたいどこに自分の欲しい情報が入っているのかが分かる.ちなみにdoxygen内部のコードにはあまりdoxygen形式のコメントが付けられていない.公式のWish Listによると,doxygenのソースコードにdoxygenコメントを付けて欲しいという要望はあるが,それに対するDifficulty Levelは10レベル中7で「結構しんどい」らしい.
手を加える
内部では様々な出力フォーマットに対応するためにOutputGeneratorを継承したHtmlGeneratorやLatexGeneratorクラスが定義されているが,残念ながら多態的な実装はされておらず,各所にif-else節が散らばっているために自前のSubClassを定義しただけでは動作しない.めんどくさい….
とはいえ今回は一部の情報を取り出したいだけなので,適当なモジュールの中に標準出力へのプリントを挟む込み形にした.というわけでクラスに関するパース情報を持っているClassDefに対してoperator << を以下のように定義してやる.
#undef strlen #include <iostream> #include <string> #define strlen qstrlen namespace { static const char* sep = " "; static const int indent_width = 1; std::ostream& indent(std::ostream& os, int indent_level) { os << std::string(indent_width * indent_level, ' '); return os; } std::ostream& brief(std::ostream& os, const MemberDef& memberDef) { if (!memberDef.briefDescription().isEmpty()) os << sep << memberDef.briefDescription(); return os; } std::ostream& print(std::ostream& os, const MemberDef& memberDef, int indent_level = 0) { indent(os, indent_level) << memberDef.typeString() << sep << memberDef.name(); brief(os, memberDef); return os; } std::ostream& print(std::ostream& os, const ClassDef& def, int indent_level = 0) { MemberNameInfoSDict *dict = def.memberNameInfoSDict(); MemberNameInfoSDict::Iterator mnii(*dict); MemberNameInfo *mni; for (mnii.toFirst(); mni = mnii.current(); ++mnii) { MemberInfo *mi = mni->first(); while (mi) { MemberDef *md=mi->memberDef; ClassDef *d1 = md->getClassDef(); ClassDef *d2 = md->category(); print(os, *md, indent_level + 1); os << std::endl; ClassDef *def = Doxygen::classSDict->find(md->typeString()); if (def) print(os, *def, indent_level + 1); mi = mni->next(); } } return os; } inline std::ostream& operator << (std::ostream& os, const ClassDef& def) { os << def.name(); if (!def.briefDescription().isEmpty()) os << sep << def.briefDescription(); os << std::endl; return print(os, def); } }
#undef strlenは,内部で使っているqtoolsとMSVCとの衝突を避けるために入れている.上記のコードを,doxygen.cppのgenerateClassList関数の上に追加.そしてgenerateClassListの中に一行コードを追加する.
static void generateClassList(ClassSDict &classSDict) { ClassSDict::Iterator cli(classSDict); for ( ; cli.current() ; ++cli ) { ClassDef *cd=cli.current(); std::cout << *cd; // この一行を追加 // 以下略
これでビルドすれば,本来の機能を果たしつつ標準出力に何かしらの情報を吐き出せるdoxygenが出来る.今回のコードだと,こんなソースを解析すると
struct Bar { int k; ///< fugafuga. int l; ///< hogehoge. }; struct Foo { int i; short j; Bar bar; ///< bar. };
こんなのを吐き出すようになった.自分が欲しいのはCの構造体に対するテキストファイルだったので,メンバ関数の存在は考慮されていない.あと必要無かったので修飾子も吐いていない.手抜き.そこらへんも必要ならClassDefやMemberDefのgetterを使えば良いはず.
Bar bar int k fugafuga. int l hogehoge. Foo int i short j Bar bar bar. int k fugafuga. int l hogehoge.
今回大したコードは書いてないので,ちょっと手を加えればYAMLでもJSONでも好きな形式に変更するのは簡単.デフォルトだと解析途中にメッセージも標準出力に吐き出すので,DoxyfileでQUIET=YESにしておくと良い.
まとめ
コード解析してちょっと何か出力したいなーという時,良いツールが無ければdoxygenに乗っかると楽できるかも.