LokiのGenScatterHierarchyを継承して使う
Lokiのタイプリストを使ったGenScatterHierarchyというやつは結構面白いんですが,それを継承したクラスでFieldヘルパを使おうとすると(VS2010では)コンパイルが通らない.
template <class T> struct Foo { std::vector<T> value_; }; template <class TList> class Bar : public Loki::GenScatterHierarchy<TList, Foo> { public: template<int i, class T> void push(T value){ Loki::Field<i>(*this).value_.push_back(value); } }; int main(void) { Bar< TYPELIST_5( int, int, double, double, std::string ) > list; list.push<0>(5);//最初のintに5をpushしたい }
error C2594: '初期化中' : 'Bar<TList>' から 'Loki::GenScatterHierarchy<AtomicType,Unit> &' への変換はあいまいです。
基底クラスにLeftBaseがいっぱい有るぞ!どういうこっちゃ!っていう事らしい.単純に,GenScatterHierarchyにint型のテンプレート引数を追加してみる.
template <class TList, template <class> class Unit, unsigned int Idx=0> class GenScatterHierarchy; template <class T1, class T2, template <class> class Unit, unsigned int Idx> class GenScatterHierarchy<Typelist<T1, T2>, Unit,Idx> : public GenScatterHierarchy<T1, Unit, Idx> , public GenScatterHierarchy<T2, Unit, Idx+1> { public: typedef Typelist<T1, T2> TList; typedef GenScatterHierarchy<T1, Unit, Idx> LeftBase; typedef GenScatterHierarchy<T2, Unit, Idx+1> RightBase; template <typename T> struct Rebind { typedef Unit<T> Result; }; }; template <class AtomicType, template <class> class Unit, unsigned int Idx> class GenScatterHierarchy : public Unit<AtomicType> { typedef Unit<AtomicType> LeftBase; template <typename T> struct Rebind { typedef Unit<T> Result; }; }; template <template <class> class Unit, unsigned int Idx> class GenScatterHierarchy<NullType, Unit, Idx> { template <typename T> struct Rebind { typedef Unit<T> Result; }; };
こうすると左から順にGenScatterHierarchy
参考:reoccuring types in a Loki::Tulpe - comp.lang.c++.moderated
クラスの継承関係をコンパイル時に検出する
Modern C++ Designから.
template<class T, class U> class Conversion { typedef char Small; class Big{ char dummy[2]; }; static Small Test(U); static Big Test(...); static T MakeT(); public: enum { exists = sizeof(Test(MakeT())) == sizeof(Small) }; }; int main(void){ std::cout << Conversion<int,double>::exists << std::endl; //1 std::cout << Conversion<char*,double>::exists << std::endl; //0 }
sizeof演算子がコンパイル時にサイズを評価することを利用.BigとSmallはサイズが違えば何でもいいけど,こう書いておけば処理系に依らずに同じ結果を出してくれる.コンパイル時評価にしか使わないので,当然Test(U),Test(...)に実体は必要無い.
たとえばテンプレートクラスで,テンプレート引数の型情報に応じてコンストラクタの処理を変えたい場合なんかに使うことができる.
template<int i> struct Int2Type{ enum { value = i }; }; class Base{}; template <class T> class Hoge { public: Hoge(){ Foo(Int2Type<Conversion<T,Base>::exists>());} void Foo(Int2Type<1>){/*TとBaseに互換性があるときはこちらで初期化*/} void Foo(Int2Type<0>){/*それ以外のときはこちらで初期化*/} };
部分特殊化と違って,メンバ関数の部分特殊化の問題をクリアできること,スケーラブルであることが嬉しい.でもキモいっちゃキモい.
追記
boost::is_convertibleというのがあるらしい.知らなかった…
MacBookAir欲しい日記改めSpinを使ったモデル検査入門
明けましておめでとうございます.今日はMacBookが欲しいので日本語の情報がちょっと少ないので,修論関係で触っているモデル検査ツール,Spinについて軽くまとめてみます.
モデル検査とは
厳密さに欠ける言い回しでアレですが,「間違いなく正しく動くソフトウェア」が欲しいときにどうするか.テストはバグの早期検出に有効ですが,テストで得られるのは
「テストで検査した範囲においてソフトウェアが仕様を満たす」
という結論であって,当然
「すべての範囲においてソフトウェアが仕様を満たす」
ことではありません.たとえば人工衛星みたいなクリティカルな組み込み分野だと,「そのコードで『人工衛星の角速度が発散しない』ことを証明できるのかねキミ?衛星はメンテナンスできないってこと位分かってるよね?」とか言われた日には,テストケースを書いた我が脳味噌の完璧さに全てを賭けるか,泣きながら宇宙服の調達を開始するかの二択を迫られることになります….
しかしながら後者の結論を得るには,よほど単純なコードでも無い限りは総当たりによる検査を行わざるを得ません*1.モデル検査とは,その総当たりを実際に行ってしまい,「間違いなく正しく動く」ことを証明したり,満たされない場合の反例ケースを探し出したりすることが可能になる手法です.
但し力ずくで全状態空間を探索することもあって,実際には検査する対象はソースコードではなくそのモデルであることに注意が必要です.プログラマはシステムを忠実に表現し,かつ充分に簡潔なモデルをコードとは別に用意する必要があります*2.
Spin
ともかく,今回はSpinというモデル検査ツールを使って,簡単な検証を行ってみます.環境の導入はSpinのインストールなどを参考にすれば簡単*3.SpinではPromelaというモデル記述言語を使ってシステムをモデル化します.とりあえず,ある変数iを1つインクリメントするだけのPromelaモデルを書いてみます.
int i = 0; active proctype P(){ printf("hello,world!"); i++; }
Promelaの文法はC言語的で,実際コンパイル時にはCプリプロセッサを最初に呼び出すため,#includeや#define文なんかが普通に使えます.ただしモデル記述言語であるために,あまり高度なことはできません.オブジェクト指向どころか,関数呼び出しも浮動小数もサポートしない男前っぷり*4…!それ故文法はとても簡単なのですが,ここでは文法の参考になりそうなページを纏めておくにとどめます.
- Promela Manual Pages -- Index
- 公式マニュアル(英語).当然一番詳しい.
- 0.PROMELAの基本文法
- 初心者向け解説.
- http://www002.upp.so-net.ne.jp/mamewo/spin.html
- Promelaのサンプルコードなど.
- SPINによるモデル検査
- Spin入門のスライド.
- ツール:SPIN(Promela言語) - 佐々研・PukiWiki
- Spin/Promelaに関するメモ.後半は割と悲哀にあふれている….
線形時相論理
モデル検査を行うためには,モデルに対する検査式の記述が必要です.Spinでは線形時相論理(LTL)というものを使います.
線形時相論理 - Wikipedia
LTLがとても強力なのは,「いつかAが真になる」とか,「Aが真になるまでの間,Bは真である」といった表現が簡単にできる点.SpinにおけるLTL式の表記を下にまとめておきます.下4つがLTLに特有の記号(詳しくはWikipediaなどを参照).たとえば「iがいつか1になる」をSpinで表現すると「<>(i==1)」となります.「iが0になったら,その後は必ず0→1→2→3と推移する」という性質は,i==nという論理式をqnと定義すると,「G( q0 -> ( ( q1 U q2) U q3) )」というUntilの入れ子で表現できます.
| 記号/結合子 | 意味 | Spinでの記法 |
| and | && | |
| or | || | |
| not | ! | |
| imp | -> | |
| G | 常に〜が成立する(Globally) | [] |
| F | いつか〜が成立する(Finally) | <> |
| U | 〜となるまで…が成立する(Until) | U |
| X | 次の時点で〜が成立する(Next) | X |
例:モデル記述
では,さっそく例を考えてみます.「応募を表明したユーザーの中から抽選で1名にMacBookが当たる」というキャンペーンを想定してみましょう.こんなモデルを作ってみます.
01: /* campaign.pml */ 02: bool want_iMac[2]; 03: bool get_iMac[2]; 04: bool campaign = true; 05: 06: active [2] proctype User() provided(campaign){/*campaign==trueのときにだけ実行可能なプロセス*/ 07: do 08: :: want_iMac[_pid] = true; 09: printf("MacBook Air 11インチ欲しい!"); 10: :: want_iMac[_pid] = false; 11: printf("MacBook Air 11インチ欲しくない…"); 12: od 13: } 14: 15: active proctype Hatena(){ 16: do 17: :: 18: campaign = false;/*キャンペーン終了*/ 19: if 20: ::want_iMac[0] ->/*0が当選*/ 21: get_iMac[0] = true; 22: get_iMac[1] = false; 23: ::want_iMac[1] ->/*1が当選*/ 24: get_iMac[0] = false; 25: get_iMac[1] = true; 26: ::else ->/*応募者が0*/ 27: get_iMac[0] = false; 28: get_iMac[1] = false; 29: fi; 30: campaign = true;/*次のキャンペーン開始*/ 31: od 32: }
Userプロセスが2つ,Hatenaプロセスが1つ存在しており,どれもactive宣言(つまり,初期状態から実行可能)されています.Promela言語は実行可能なプロセスの中から非決定的に次のプロセスを選択して1行進めていきます.User[0]の7行目を実行→Hatenaの16行目を実行→User[1]の7行目を実行…といった感じ.
do...odやif...fiブロックで囲んだ構文はPromelaに独特の非決定的な分岐選択文で,->符号左側の式が真と評価されたものの中から,ランダムに分岐先が選択されます(左辺が省略された場合は常にtrue).これも詳しくはPromela言語のリファレンスを参考に.それぞれのプロセスの動作を日本語で表現すると,以下のような感じでしょうか.
User:「キャンペーンの間,自身に対応したwant_iMacの値をtrueまたはfalseに更新する.」
Hatena:「キャンペーン終了後,iMacを欲しがっているUserから1人を当選者として選び,次のキャンペーンを開始する.但し応募者が0の場合は当選者を選ばない.」
例:LTL式による検査
この懸賞に必要な条件は色々あるはずですが,とりあえずこんな条件式を考えてみましょう.
「当選者の数は常に1名以下である」
これをLTL式で表現すると,「[](get_iMac[0] + get_iMac[1] < 2)」と書けます*5.さっそくこれをSPINでの検証にかけてみます.
spin -a -f "[](get_iMac[0] + get_iMac[1] < 2" campaign.pml gcc -o pan pan.c ./pan
するとerrors:1と,何と与えたLTL式が満たされないことが判明しました.反例を出力してみます.
spin -g -l -p -r -s -t -X -u250 campaign.pml
Process Statement want_iM[0] want_iM[1]
2 Haten 18 campaign = 0 0 1
Process Statement campaign want_iM[0] want_iM[1]
2 Haten 23 want_iMac[1] 0 0 1
2 Haten 24 get_iMac[0][0] 0 0 1
2 Haten 25 get_iMac[1][1] 0 0 1
Process Statement campaign get_iMa[0] get_iMa[1] want_iM[0] want_iM[1]
2 Haten 30 campaign = 1 0 0 1 0 1
1 User 10 printf('iMac欲し 1 0 1 0 1
1 User 11 want_iMac[pid] 1 0 1 0 1
0 User 9 want_iMac[pid] 1 0 1 0 0
2 Haten 18 campaign = 0 1 0 1 1 0
2 Haten 20 want_iMac[0] 0 0 1 1 0
2 Haten 21 get_iMac[0][0] 0 0 1 1 0
2 Haten 22 get_iMac[1][1] 0 1 1 1 0 出力は左から順にプロセスID,プロセス名,ソースの行番号,ソースの内容(一部),その時点における状態量となっています.どうやら,1番が当選した(25行目)次のキャンペーンで0番が当選(21行目)すると,その瞬間に両者とも当選したかのような状態となってしまうようです.この瞬間に当選情報がユーザーに公開されていると,前回の当選情報が残っている1番のユーザーが「【拡散希望】【一人でも多くの人に知ってほしい】【知らないでは済まされない】連続当選なう!」と勘違いtweetを広めてしまう悲劇に見舞われます….atomicというブロックで19〜29行目を囲うと,今度はこのエラーは生じず,LTL式が真であると判定されます.atomicの追加に相当する仕様/実装側の変更(当選判定の計算中は,ユーザーから当選者の確認ができないようにするetc)が必要になることが分かりました.
15: active proctype Hatena(){ 16: do 17: :: 18: campaign = false;/*キャンペーン終了*/ 19: atomic{/*atomic内部にいる間は検査式が判定されず,他プロセスも実行されない*/ 20: if 21: ::want_iMac[0] ->/*0が当選*/ 22: get_iMac[0] = true; 23: get_iMac[1] = false; 24: ::want_iMac[1] ->/*1が当選*/ 25: get_iMac[0] = false; 26: get_iMac[1] = true; 27: ::else ->/*応募者が0*/ 28: get_iMac[0] = false; 29: get_iMac[1] = false; 30: fi; 31: } 32: campaign = true;/*次のキャンペーン開始*/ 33: od 34: }
まとめ
「仕様の記述」と「モデルの検査」という作業を通じて,
- あいまいな仕様を明確化させることができる
- システムの正しさを保証することができる
という2つのメリットを手に入れることが出来ました.先に挙げた例くらいならふつうに気が付けるかもしれませんが,例えばUserプロセスに「ユーザーはいつでもはてなを退会できる」というモデルを追加すると,まだ考え足りない仕様があることに気づきます.
個人的に使ってみた感想としては,非決定的な動作という点にさえ慣れてしまえば,文法的には非常に身に付けやすく,予想以上に低いコストで導入できるなーという感じです.環境も一瞬で整うので,「形式手法」とか「時相論理」なんて固い名称に怖気づかずに,ぜひ気楽にトライしてみるといいんじゃないでしょうか.
参考文献
")
モデル検査 初級編―基礎から実践まで4日で学べる (CVS教程)
- 作者: 産業技術総合研究所システム検証研究センター
- 出版社/メーカー: ナノオプトメディア
- 発売日: 2009/11
- メディア: 単行本
- 購入: 2人 クリック: 36回
- この商品を含むブログ (1件) を見る
![【楽天ブックスなら送料無料】SPINモデル検査入門 [ M.ベン・アリ ]](http://thumbnail.image.rakuten.co.jp/@0_mall/book/cabinet/2742/27420844.jpg?_ex=128x128 "【楽天ブックスなら送料無料】SPINモデル検査入門 [ M.ベン・アリ ]")
ところで
応募方法はかんたん。あなたのブログ(はてなダイアリー)に、「MacBook Air 11インチ欲しい!」と書きこむだけで、応募完了です。応募の際には、MacBook Airや今年のブログ生活にかける、あなたの想いをぜひ書きこんでください!
MacBook Air 11インチ欲しい!とは - はてなキーワード
と書いてあったのでコード中に書いたんですが,認識されていない….これもモデル検査で検出できる類の仕様の曖昧さかと思います(ドヤ顔).というわけで改めてMacBook Air 11インチ欲しい!
*1:「仕様Aが常に真である」というような恒真問題は一般的にco-NP問題であるから,決定性チューリング機械によって多項式時間で解くことはできないとか何とか
*2:モデルからコードを生成する試みも色々と行われているようです
*3:1つだけ追加すると,公式のGUI環境(iSpin/XSpin/jSpin)でモデルを書くより,Emacsのpromela-mode.elを使ったほうが100倍効率的
*4:ただしマクロ的に展開されるインライン関数を使ったり,C言語のソースを埋め込むことはできる.詳しくは公式マニュアル参照
*5:Promelaにおけるbool型はbyteのシンタックスシュガーなので,true + trueは2と評価される
引数を参照とポインタのどちらで渡すか
暫く触っていないとすぐ忘れるのでメモ.クラスを関数の引数に取るとき,参照で渡すかポインタで渡すか?結論をさっさと書くと,constなら参照,非constならポインタをデフォルトとする.constポインタはconst参照の使用が合理的でない場合に使える.非const参照は使ってはいけない.
| constの有無 | ポインタ | 参照 |
|---|---|---|
| const | △ 使える | ○ 推奨 |
| 非const | ○ 推奨 | × 使ってはいけない! |
結局好みの問題でもある気がするけど,GoogleのC++スタイルガイド,プログラミング言語C++第3版,大規模C++ソフトウェアデザインあたりでも上と同じような主張がされているということで正当化してみます.
なぜ非constの参照がまずいのか
引数が変更されるかどうかが構文だけから分かりにくい.たとえば以下のコードでcが意図せず変更されてしまったとき,どの関数が悪さをしているのか調べるために,ヘッダファイルを探し回る羽目になる.
int main(void){ Class c; foo(c);// void foo(const& Class); in foo.h bar(c);// void bar(&Class); in bar.h baz(c);// void baz(const& Class); in baz.h }
「非constならポインタである」という規則を一貫して守っておけば,ユーザーは引数に&をタイプするとき,それが関数側で変更される可能性があることを認識できる.
int main(void){ Class c; foo(c);// const bar(&c);// 非constの可能性がある! baz(c);// const }
const参照ではなくconstポインタを使うケース
(1)STLアダプタみたいな,const参照を使うことができない場合.
(2)オブジェクトの生存期間中にその引数が有効である必要があることを強調したい場合.
以下のケースではadd関数はbのコピーを取らずにアドレスを持つため,bはfの生存中に有効である必要があるが,呼出し側からはそれが分かりづらい.ポインタであれば,その危険性に気づきやすい…かもしれない.Googleのガイドでは,こういう場合にはコメントに明記するのがベストだと書かれている.
class Foo { private: const Bar* bar_; public: void add(const Bar& bar){ this->bar_ = &bar; } }; int main(void){ Foo f; Bar b; f.add(b);//const参照渡し.Fooの内部にbのアドレスを保持 }
(3)const参照による暗黙の一時オブジェクト生成を嫌う場合.
class Class { private: const Class* myclass; public: Class(int i); void set(const Class& c) { this->myclass = &c; } const Class* get() const { return this->myclass; } }; int main(void){ Class a(10); a.set(1);//一時オブジェクトが生成 //オブジェクトはsetの関数内でのみ有効であることが保障される Class* b = a.get(); //bで何かする→! }
a.setにint型を渡したことで,setのスコープ内でのみ有効なClassの一時オブジェクトが生成される.そのオブジェクトへのポインタをClass内部で持とうとすると,よろしくない事態になる.
この場合,(1)引数を非const参照にする,(2)引数をconstポインタにする,(3)Classのコンストラクタをexplicitとして宣言する,のいずれかの変更を行うと,一時オブジェクトを生成しないためコンパイルエラーを出すようになる.ただし(1)は冒頭から否定しているので,取りうるのは(2)か(3)のみ.ライブラリに手を加えられない場合は,引数をconstポインタにすることになる.
.NETでVisioクローンを作りたい
Visio的なUIを持ったフォームアプリケーションを作りたい,ということでOpendiagramというオープンソースの.NET用ライブラリを使ってみた.
Open Diagram - Home
ちょっと木構造を書くくらいなら簡単で,こんな感じに書けばVisio的なパレットの上に移動,拡大縮小が可能なモデルがぽいぽい置かれる.
Model model = this.diagram1.Model; diagram1.Model.SetSize(new Size(1000, 1000)); //親ノードの配置 Shape shape = new Shape(); shape.Location = new PointF(300, 50); model.Shapes.Add("parent", shape); //子ノードの配置 shape = new Shape(); shape.Location = new PointF(200, 200); model.Shapes.Add("child1", shape); shape = new Shape(); shape.Location = new PointF(400, 200); model.Shapes.Add("child2", shape); //エッジの配置 TreeLine treeLine = new TreeLine(); treeLine.AddStart(model.Shapes["parent"]); treeLine.AddEnd(model.Shapes["child1"]); treeLine.AddEnd(model.Shapes["child2"]);
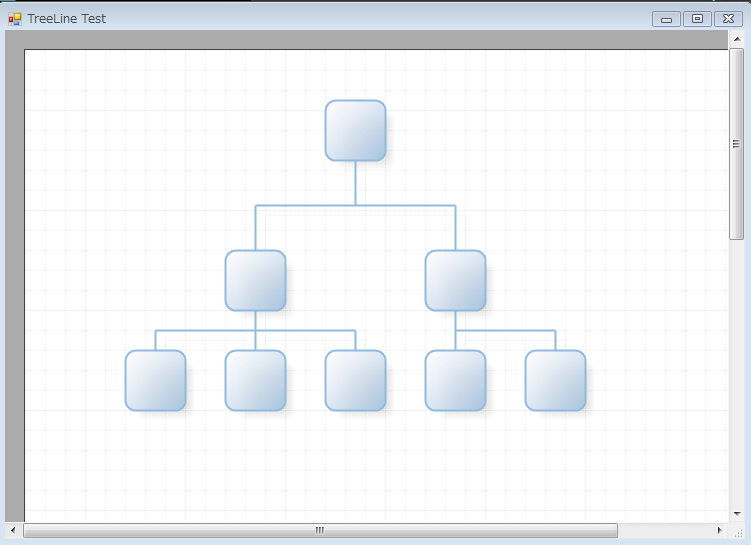
UML的な図もさっくり書けた.
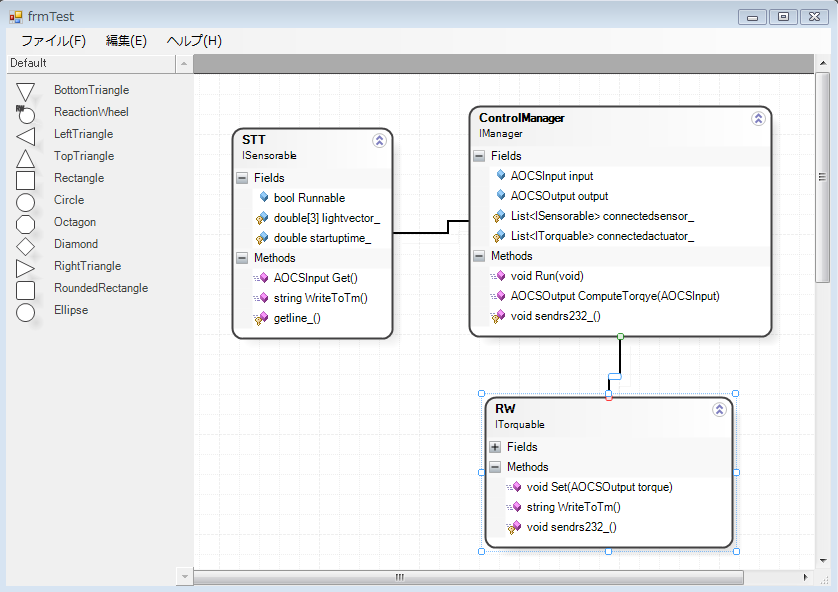
んで,これを使ってちょっとしたアプリケーションを作ろうしているのだけど,どうも色々嵌りどころがありそうな感じ(コピペの実装をするためだけに元のコードを数か所いじる必要があった…).あまり活発なプロジェクトではないようなので,使用例も見つけづらいのが残念.ちなみにこのプロジェクト自体は以下のページで知った.
参考:C# で使えるグラフやチャート系ライブラリのまとめ - アジャイルプログラマの日常
あとは,Visioを持ってるのであればVSと相互運用が可能なので,ここらへん参考にまるごと組み込んでしまうほうが素直なのかもしれない.
Drawing Visio Shapes in the Visio ActiveX Control Using C# and .NET
Programming with the Microsoft Office Visio 2003 ActiveX Control